Comprendre les termes de Stable Diffusion
Les termes techniques de Stable diffusion décryptés pour ne pas faire tes réglages à l'aveugle !


Le type particulier d'IA auquel appartient Stable Diffusion a une terminologie particulière qu'il s'agit de comprendre pour savoir quels réglages faire.
Checkpoints ou Model : les différents Modèle d'IA
Les checkpoints sont les modèles d'IA, c'est-à-dire une version bien particulière de Stable diffusion comme SD-XL.
Le modèle d'IA est un gros fichier de l'ordre de 4 à 6GB dont l'extension est par exemple .safetensor et qui est copié en local.
On peut soit le télécharger manuellement depuis des sites comme Hugging Face ou CivitAI ou bien installer Stable diffusion et les modèles d'IA via une interface.
Il est important de distinguer les modèles de base de Stable Diffusion : 1.5, XL, Flux....
Des modèles spécialisés qui sont affinés (finetuné) pour avoir un rendu particulier, par exemple Epic Realism basé sur la version 1.5 de Stable Diffusion.
En général, on utilise un modèle affiné avec un rendu qui nous intéresse, mais qui est basé sur un modèle de base particulier qui est important de connaître.
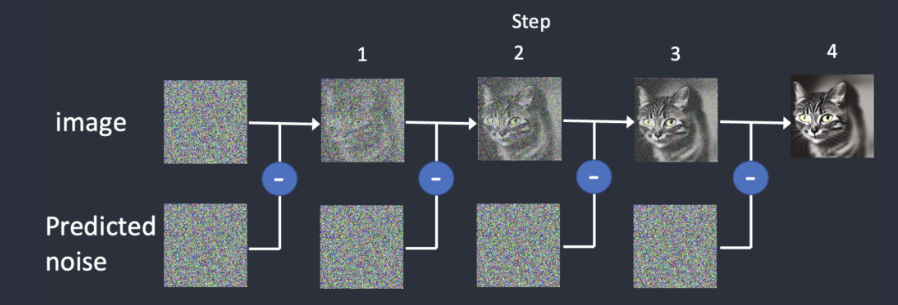
Sampling steps :(Étapes d'échantillonnage)
Les étapes d'échantillonnage correspondent aux nombres d'itérations qui sont nécessaires pour réaliser une image. En effet, le processus de création d'une image en partant d'une image totalement bruitée (ou image latente) jusqu'à l'image finale demande un certain nombre d'étapes.
Au bout d'un certain nombre d'étapes cependant, l'image ne se modifie plus et il n'est pas nécessaire par exemple de régler ce paramètre à 50 par exemple.
En dessous de 15, la qualité de l'image commence à se dégrader.
On peut comparer les étapes, ou steps, au développement d'une photo en noir et blanc. Si on ne laisse le tirage photo pas assez longtemps dans le révélateur, il sera pâle, presque fantomatique. En revanche, si on le laisse trop longtemps, le papier sera entièrement noir.
De la même manière, il existe une plage idéale de nombre d'étapes qui varie suivant les modèles, mais est entre 15 et 30 en général.
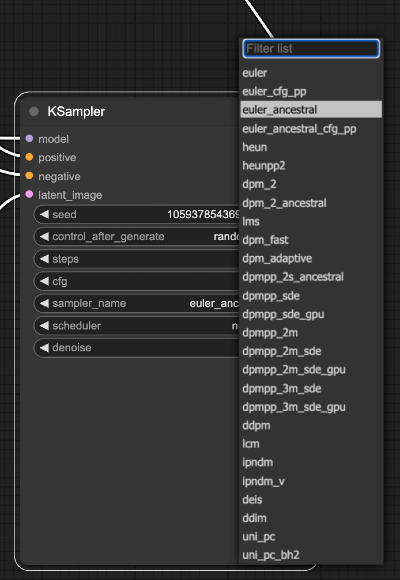
Sampler (Échantillonneur) : le cœur du rendu avec l'IA
Pour simplifier un peu les choses 🙁, il existe une longue liste d'échantillonneurs, c'est-à-dire d'algorithme pour faire l'opération que fait l'IA à chaque étape pour débruiter l'image.
Cet article en anglais détaille les différents échantillonneurs (sampler) et leurs avantages ou inconvénients.
On peut partir sur Euler qui est le sampler le plus simple
La seed : L'unicité de l'image
La seed (ou graine) est un numéro aléatoire, qui définie l'image latente qui a servi de base au processus de génération.
Le fait que l'image latente soit choisie au hasard, donne un côté aléatoire et permet de générer des images à chaque fois différentes.
Cependant, si on veut garder la cohérence entre les images, par exemple quand on veut générer plusieurs images cohérentes d'un même bâtiment. Il est important de fixer la seed.
Un autre cas où on peut vouloir la fixer et donc enlever son caractère aléatoire est quand le rendu de l'image nous convient et que l'on veut l'affiner en jouant sur un autre paramètre.
Le CFG (Classifier-Free Guidance) : La créativité
Le but de ce paramètre est de donner de la liberté ou pas à l'IA pour interpréter à partir du prompt, donc il s'agit en quelque sorte de la créativité par rapport au prompt textuel.
Plus la valeur est basse, plus l'IA est créative, c'est-à-dire qu'elle ignore le prompt totalement à 1.
Plus la valeur est haute, moins elle est créative. La valeur par défaut étant à 8. Une valeur de 20 par exemple est très élevée.
Mais il ne faudrait pas penser que plus la valeur est haute, plus le résultat est de qualité. En effet, une fidélité trop grande au prompt, peut produire des résultats incohérents.
En deçà et au-delà d'une certaine valeur, le résultat se dégrade, donc de la même manière que pour les étapes d'échantillonnages, il faut tester pour évaluer les plages adaptées en fonction du modèle que l'on utilise.
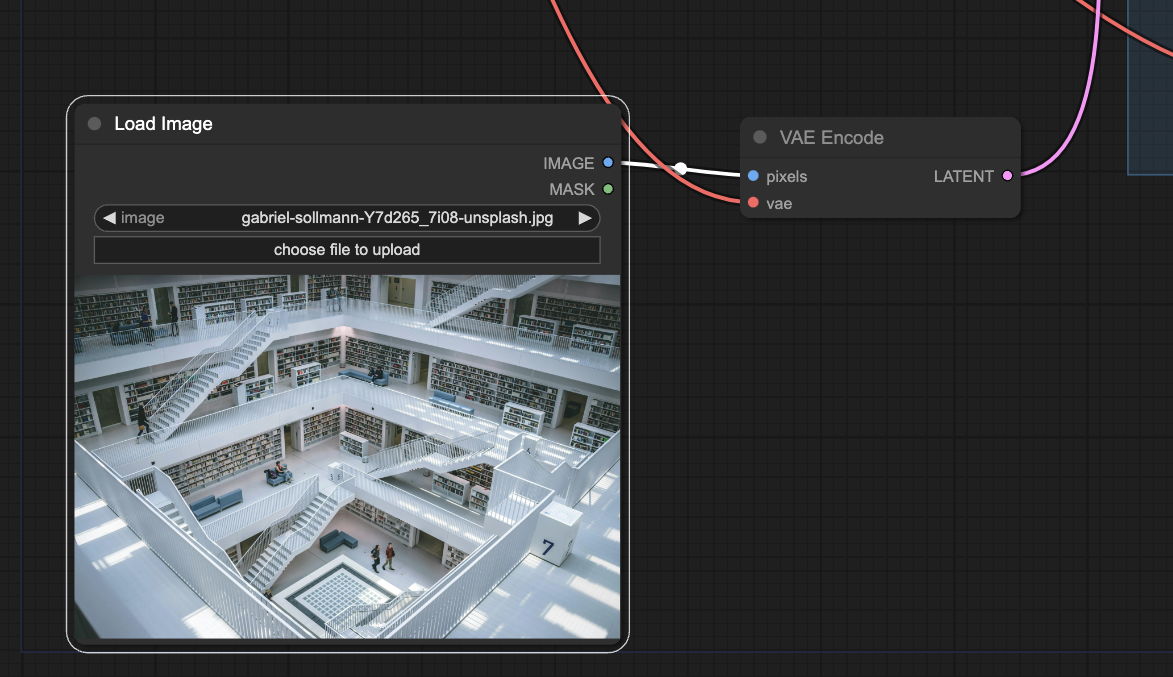
VAE : Un convertisseur vers et depuis l'espace latent
Le VAE ou Variable Auto Encoder, est un modèle qui convertit des images vers un autre format plus compressé appelé Espace Latent et avec lequel le modèle de Stable Diffusion travaille.
Donc encoder une image avec le VAE, permet d'utiliser cette même image dans le processus de génération, par exemple quand on veut créer des images à partir d'une image de base.
Il est utilisé pour alimenter le K-sampler (la partie du processus qui traite vraiment l'image) ou bien pour décoder l'image produite de manière à ce qu'elle soit visible normalement.
Par exemple, dans cet exemple, une image, donc composée de pixels, est convertie dans l'espace latent par le modèle VAE pour servir d'image de base à modifier par l'IA.
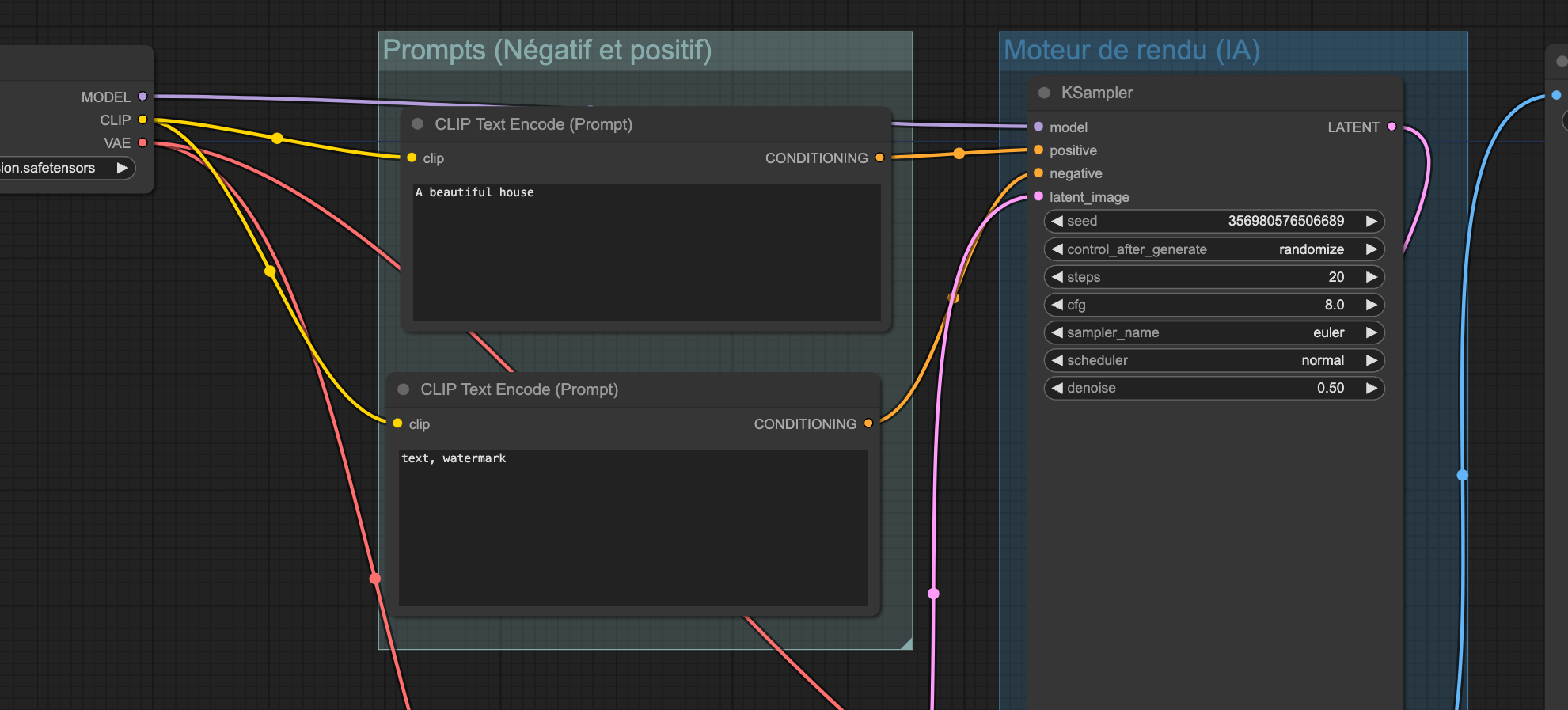
CLIP : Un traducteur de prompt
Dans un modèle de diffusion, le modèle d'IA auquel Stable diffusion appartient, il y a un modèle d'IA spécialisé, qui permet de comprendre ce que l'utilisateur a écrit, donc le prompt.
Ce modèle s'appelle CLIP et a comme rôle de convertir un prompt textuel, en un format que le modèle peut comprendre.
Dans ces nœuds de ConfyUi, on voit que le CLIP est utilisé pour alimenter le KSampler avec les prompts positifs et négatifs de l'utilisateur.
Si tu souhaites te former à utiliser l'IA pour les images d'architecture, tu pourrais être intéressé par ma formation aux images IA pour les architectes.
Dans cette formation, je t'apprends à créer ton propre système de production d'images avec l'IA en utilisant Stable diffusion. Pour trouver des inspirations, créer des rendus ou modifier rapidement des images avec l'IA.